


The Death of Evidence Based Medicine
Why we can't "trust the science"

How We Went Wrong

Why is it so difficult to get a doctor to change their minds? It seems a little counter-intuitive: doctors are trained first as scientists, shouldn’t they be the most open to new evidence? The reason why most doctors can dismiss almost all non-conforming thoughts and arguments without any moral or logical qualms is because of evidence based medicine.
From our first day in medical school to our last rotation, medical students are taught that we must practice evidence based medicine. The goal of evidence based medicine is to remove luck out of treatment outcomes. Basically, we want to ensure that every single patient we treat is receiving the best possible treatment as opposed to one that only works due to luck or the placebo effect. In order to achieve this goal, doctors prescribe treatments that have been shown effective in large, double-blinded, randomized controlled clinical trials.
Nowadays, the principle of evidence based medicine has become so widely accepted within the medical field that it more closely resembles religion than science. As long as a drug has been shown to work in large clinical trials and in meta-analyses, most doctors will accept it. At that point, trying to convince them of a possible uncaptured adverse effect will almost always be dismissed with comments such as “the data does not support that claim”. Doctors quickly begin to resemble religious zealots when they refuse to consider that their “sacred clinical trials” could ever be wrong in a large and systematic way.
As you can imagine, the pharmaceutical industry has also caught on to this religious fervor. Pharmaceutical companies know that if they can produce “research” showing that their drug works, doctors will dutifully prescribe it and will seldom question its efficacy. Therefore, in order to guarantee sales and profits, they’ve implemented several strategies to ensure that their research is not only published, but widely accredited and accepted.
Lies, Damned Lies, and Statistics
Producing new drugs is an expensive venture. It has been estimated that developing a single new drug can cost between $1-2 billion. In this light, it’s easy to understand why pharmaceutical companies want to do everything in their power to improve their returns and guarantee that their drug will make it to market. The only reliable way to ensure that their billion dollar investment yields returns is to influence the means that restrict entry into the healthcare market.
Pharmaceutical companies fund between 50-70% of all published clinical trials. It will come as no surprise to find that 96% of industry funded trials provide positive conclusions about that company’s product. Although this represents an obvious financial conflict of interest, many may retort “even if they fund the study, they can’t make up the data!”. While this for the most part is true, having ownership over the data and analysis allows pharmaceutical companies to implement a few nifty tricks that never fail at providing positive findings.
In my personal experience, the most common way that pharmaceutical companies ensure that their trials will both show positive results while evading valid scientific criteria is simply by sponsoring many trials at once. Pharmaceutical companies will fund multiple trials, and then cherry pick the trials that show favorable results. This is equivalent to me stating that I can flip a coin and get several heads in a row, but then flipping the coin continually until I hit my desired outcome while not showing you how many tries it took me. When doctors later look at these trials, all they see is a properly run trial demonstrated a significant improvement due to the pharmaceutical companies drug. Meanwhile, they are oblivious to the slight of hand taking place in front of them.
Another common trick employed by pharmaceutical companies is early termination of studies. By looking at early results of clinical trials and calculating whether or not the results show a difference, pharmaceutical companies can stop conducting a trial early when they observe a difference in their favor. This is essentially analogous to stopping the Super Bowl after the first team scores. In this example, it is obvious to most people that the other team could still have won if the game ran its full length. Of course, there are valid reasons for terminating trials early. Nevertheless, this strategy is purposefully abused as a method of increasing the rate of false positives.
Another rather simple tactic that can increase positive outcomes is known as “primary endpoint switching”. Imagine I am investigating whether or not a drug improves overall mortality in cancer, and so I design a trial to detect differences in overall mortality. However, I also collect data on other outcomes, such as cancer free survival rate. After I finish collecting data, I find that there was no difference in overall survival but there was a difference in cancer free survival, and so I simply publish the second outcome. Expanding on this concept, I could include all sorts of different outcomes to measure in order to maximize my chances of finding at least one positive difference. However, deciding on which one of these is my primary endpoint after the fact increases the rate of false positive findings and decreases the reliability of my study. It has been estimated that a staggering 19% of clinical trials employ primary endpoint switching.
Another statistical trick that can be used to fool physicians into thinking a drug has helped when in reality it may have had no effect is subgroup analysis. In this scenario, a trial could be designed to detect a difference in a given outcome, however, if a difference is not observed, investigators break up the data to see if any subgroup experienced a benefit vs control. For example, I could divide my original treatment group into classes of patients, such as those younger than 40, between 41-64, and older than 64. Then, I would see if any of these subgroups of patients showed improvements. The problem here is that the trial was not originally powered to detect differences in these subpopulations, and so analyzing these smaller populations effectively underpowers the trial and once more, increases the rate of false positive findings.
While fabricating data is rare, it is worthwhile noting that it does occur. In 2009, researchers conducted a survey that asked scientists if they’ve ever falsified data. The results showed that 2% of scientists admitted to personally committing fraud, while 34% admitted to conducting research in academically “questionable” ways. While those numbers may concern you, it is far more appalling to consider that 14% of scientists stated that they have colleagues who outright fabricated data. Moreover, the fact that this survey was conducted on a voluntary basis almost certainly ensures that this number is understated. Now remember the vast financial pressure exerted by pharmaceutical companies to yield positive results, and you begin to imagine the degree by which these numbers may be undercounted.
I’m sure that this is not a comprehensive list of all the statistical manipulations employed by pharmaceutical companies to effectively falsify how well their drugs work. If you know of other methods or resources that elaborate on these tricks, I would love if you could share them with me!
Financing of Academic Journals

For those of you who regularly read clinical trials and medical journals, you may be thinking that this is the part where academia steps in to stop big bad pharma from lying to us. After all, the whole point of academic journals is to “peer review” the data. Unfortunately, it doesn’t work out that way.
Pharmaceutical companies realize that if their studies do not get published in reputable journals, no doctors will read them and no doctors will prescribe their drug. The next most obvious step to guarantee that their investment will be fruitful is to influence the best academic journals by giving them money. Admittedly, the process is not quite that straight forward.
Academic journals make a lot of money by selling “reprints” to pharmaceutical companies. Basically, if one of their studies gets published in a prestigious journal like BMJ or NEJM, pharmaceutical companies will pay a handsome fee to the publisher to buy thousands of copies of their own study (which they later use as marketing material). Most journals do not openly publish how much money they make from this process. However, to their credit, The British Medical Journal (BMJ) reported that in 2020 (the most recent year I could find data on), 17.5% of their revenue came from pharmaceutical companies. The Lancet, another prestigious academic journal, published that in 2005, 41% of their annual revenue came from selling reprints. While other journals like the NEJM and JAMA do not publish how much money they make from this process, others have speculated that it is likely higher than the 41% made by The Lancet, as they both publish a higher proportion of industry funded papers and therefore are likely have a higher monetary evaluation from industry.
An obvious example of the conflict of interest at work here is demonstrated through the infamous Vioxx story. This NSAID was widely advertised and marketed in large part thanks to a trial published by the NEJM in 2000 called the “VIGOR” trial. Merck subsequently bought just shy of a million copies of the article, spending almost $700,000. When doctors and scientists brought up concerns about uncaptured adverse events, including heart attacks, the NEJM infamously ignored the doctors pleas to rescind the trial and to issue a letter of warning. While no one knows for certain why the article wasn’t pulled faster, I suspect that losing millions in profits from this article (and those in the future) may have had something to do with it.
It is ludicrous to think that an academic journal could ever objectively review an article that is being submitted by companies that contribute anywhere between 18%-50% of their annual revenue. A similar situation arose during the 2008 financial crisis, where risk assessors such as Morgan Stanley kept providing AAA ratings to CMOs that were clearly failing. History now knows how these risk assessors were complicit in contributing to the financial crisis then, and history will soon show how medical journals are lying and harming patients today.
Positive Findings Bias
One of the largest problems plaguing evidence based medicine is positive publication bias. It has been estimated that anywhere between 30-50% of all clinical trials go unpublished. Moreover, it is a well observed fact that clinical trials that show negative results are published far less frequently than ones that show positive results. How can doctors make appropriate decisions when half of all data is invisible?
In order to try and quantify how often negative results go unpublished, one group of researchers followed 74 registered clinical trials from inception to publication (or lack thereof). Of these 74 trials, over 30% (22 studies) of them went unpublished. When they dove deeper into the data, the researchers found that 37/38 trials with positive results were published, while only 14/36 trials with negative or null results were published. Even more concerning is the fact that 11 of the published negative studies were framed in such a way that misrepresented the findings as positive. Only 3/36 trials with negative or null findings were published and honestly represented their results. Finally, 21/22 unpublished trials had negative results. In other words, this study suggests that the vast majority of unpublished data is negative data, and if negative data is published, it is likely misrepresented.
This data should be alarming to anyone claiming to be practicing “evidence based medicine”. While it is not clear whether this publication bias is a result of compromised authors, lower prestige associated with publication of negative trials, or simply bias amongst journals to print such trials, the bias is clear and present. No doctor can practice true evidence based medicine if they lack access to almost half of all the evidence available.
What Doctors See
Finally, when we combine all 3 of the aforementioned systematic problems with medical trials and data available, we can visualize what doctors are actually working with when practicing “evidence based medicine”.
has come up with one of the most elegant ways of illustrating this concept. asks us to suppose we were to plot outcomes from a medical intervention or drug along a graph, where the left most extreme (on the x-axis) represents an absolutely lethal intervention (such as decapitation) and the right most extreme of the graph represents an absolutely life saving intervention (such as deploying a parachute while jumping from an airplane).Now, let’s take this same concept but apply it to clinical trials that pertain to a given drug. Here, we could say that clinical trials that showed the drug to be absolutely lethal would be represented on the left most extreme, while trials that showed the drug absolutely saved a life would be represented in the right most extreme. All the other possible outcomes would be represented on the continuum between deadly and lifesaving. Let’s additionally assume, for the sake of argument, that in reality this hypothetical drug has no effect on the average patient. Therefore, if we were to plot the results of all the clinical trials ever conducted on this imaginary drug, the results would approximate a standard distribution around the real result (as shown below).

However, what portion of the above graph would actually be seen by doctors after we factor in the systematic biases we discussed? Well, the 50-70% of trials that are funded by pharma, almost all of which show positive results, would certainly be published. On the other hand, the vast majority of negative results would probably go unpublished. Additionally, a lot of the negative trials would be reframed to misrepresent a positive outcome while a minute fraction of them would be published honestly. Finally, we must factor in a small percentage of positive trials with fabricated data.
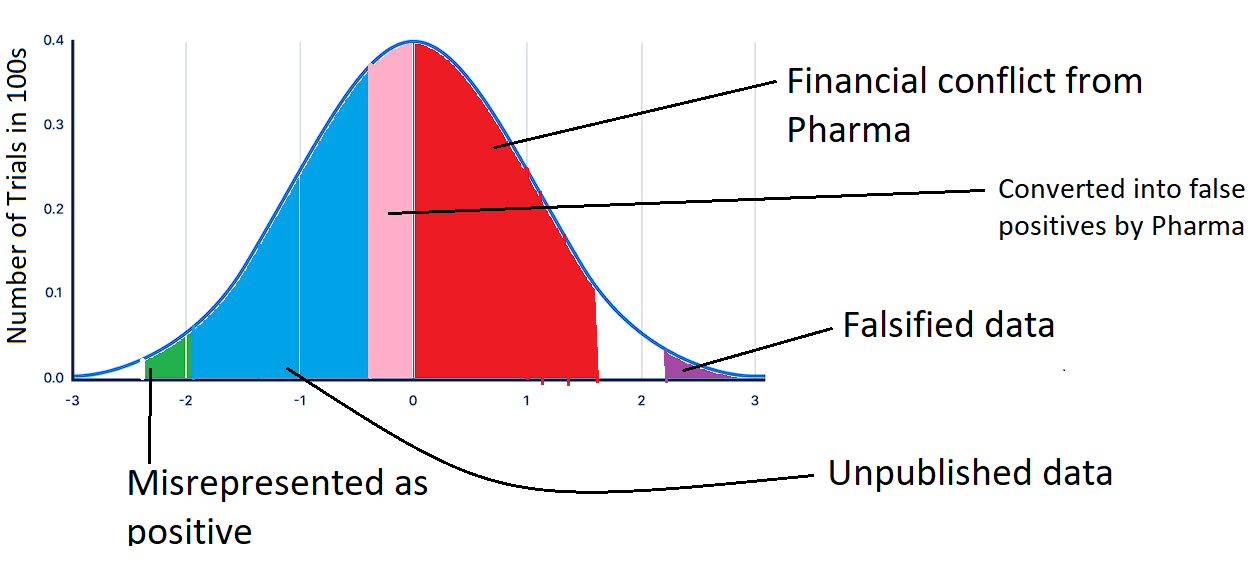
After moving the pink and the green sections of the above graph to the right of 0 (so that it represents a positive finding), and deleting the blue section (which goes unpublished), we are left with the data that doctors are actually able to see, as shown below. I apologize for the crude paint jobs, I am not a graphics designer...
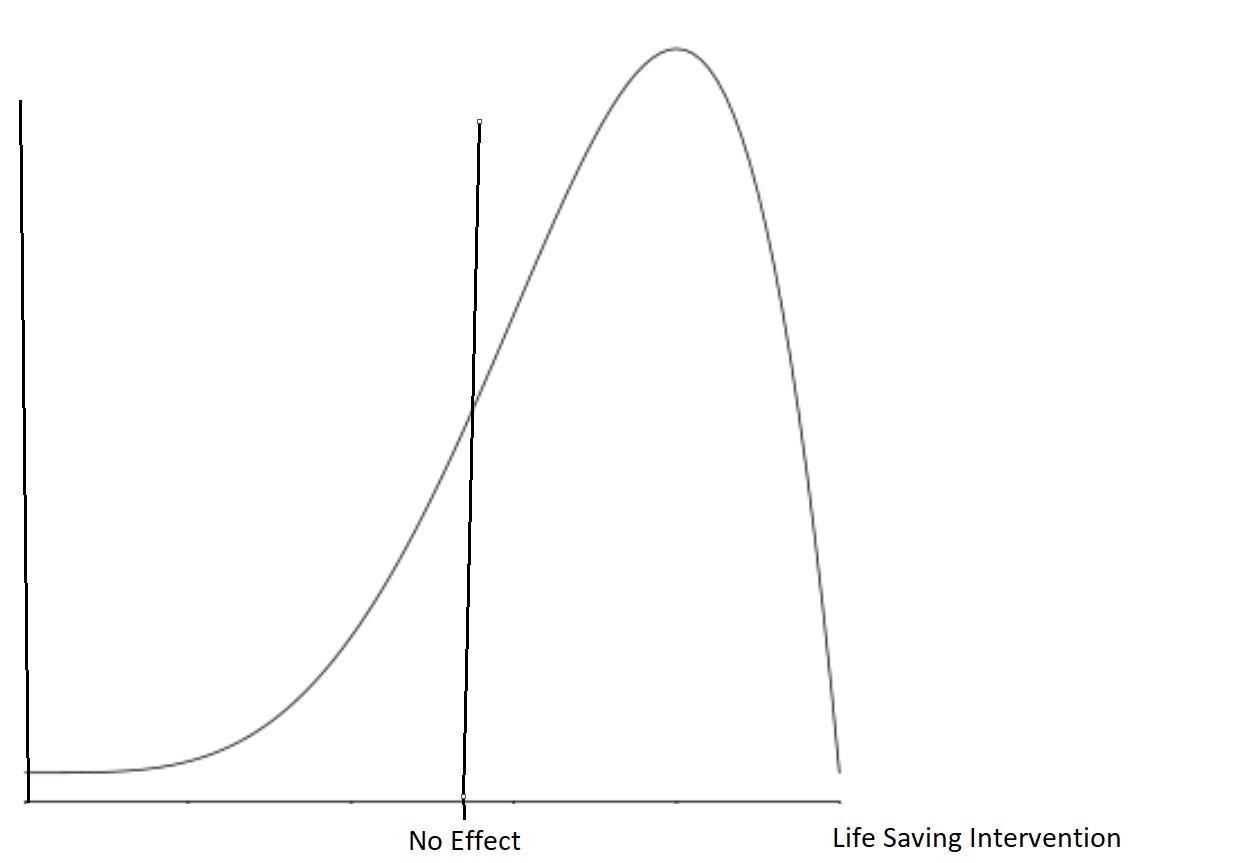
As you can tell, when a doctor analyses the totality of visible data, they see a clear consensus of the data showing that the drug benefits the average patient, even if in reality, it has no effect.
No grand conspiracy is needed. No story needs to be concocted about how every doctor in America is conspiring to harm their patients for the profit of pharmaceutical companies. Simply by controlling the data available and by statistically manipulating results in subtle ways, doctors can be duped into thinking that a drug helps their patients, even if in reality it may harm them. Moreover, because of our adamant efforts to practice evidence based medicine, doctors become extremely entrenched in their opinions by believing they are based on real science.
This is why we cannot simply “trust the science”. Our science has become so polluted that it may actually be entirely unusable. If medicine is to have a chance of correcting its course, its rotten foundation must be torn up and re-laid.
Thank you very much for reading, please consider supporting this newsletter with a free subscription!